By going through these CBSE Class 12 Chemistry Notes Chapter 14 Biomolecules, students can recall all the concepts quickly.
Biomolecules Notes Class 12 Chemistry Chapter 14
Carbohydrates: Most common examples of carbohydrates are glucose, fructose, cane sugar, starch etc. Most of them have a general formula Cx (H2O)y. Earlier they were considered hydrates of carbon. For example, glucose C6H12O6 fits into this general formula C6(H2O)6 But even acetic acid (CH3COOH) fits into this general formula C2(H2O) and it is not a carbohydrate. Similarly, rhamnose, C6H12O5 is a carbohydrate but does not fit into this definition.
Chemically, the carbohydrates may be defined as optically active polyhydroxy aldehydes or ketones or the compounds which produce such units on hydrolysis.
They are classified as:
- Sugars: They are sweet in taste and water-soluble, e.g. glucose, fructose, sucrose.
- Non-sugars: They are tasteless and water-insoluble, e.g., starch, cellulose. Carbohydrates are systemically classified as:
1. Monosaccharides: A carbohydrate that cannot be hydrolysed further to give simpler units of polyhydroxy aldehydes or ketones is called monosaccharides. Glucose (C6H1206) is an aldohexose and fructose (C6H1206) is a ketohexose.
2. Oligosaccharides: Carbohydrates that yield two to ten monosaccharides on hydrolysis are called oligosaccharides.
(a) Disaccharides: They hydrolyse to give two units of monosaccharides. They include sucrose, maltose, lactose.
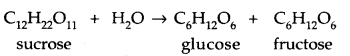
(b) Trisaccharides: They yield three units of monosaccharides on hydrolysis, e.g. C18H32O16 (raffinose).
(c) Tetrasaccharides: Yields four units of monosaccharides on hydrolysis, e.g. stachyose C24H42O21
2. Polysaccharides: They yield a large number of monosaccharide units on hydrolysis: Common examples are starch, cellulose. They are not sweet in taste.
Reducing sugars are those which reduce Fehling’s solution and Tollen’s reagent. All monosaccharides whether aldoses and ketoses are reducing sugars.
Sugars that do not reduce Fehling solution or Tollen’s reagent are termed as non-reducing e.g., sucrose.
→ Monosaccharides: They contain three to seven carbon atoms. If they contain an aldehyde group (- CHO), they are termed aldoses. If they contain a keto group (C = O), they are termed ketoses.
Different Types of Monosaccharides:
1. Glucose:
Preparation:
(a) From Sucrose (Cane Sugar)

(b) From Starch:
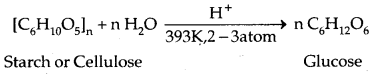
→ Structure of Glucose: It is an aldohexose and is also known as dextrose. Its structure (open chain) is
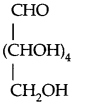
Evidence in favour of the above structure:
- Its molecular formula was determined to be C6H12O6.
- On heating (prolonged) with HI, it formed an n-hexane suggesting that all the 6 carbon atoms are in a straight chain.
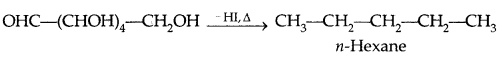
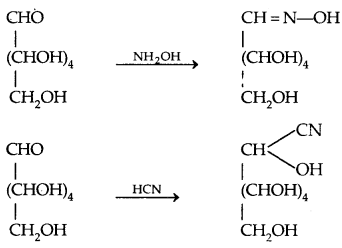
- It reacts with hydroxylamine to form an oxime and adds a molecule of hydrogen cyanide (HCN) to give cyanohydrin showing the presence of a carbonyl group in it,
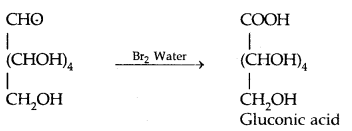
- Glucose is oxidised to gluconic acid by mild Oxidizing agent Br. water, confirming that a carbonyl group is an aldehyde group.
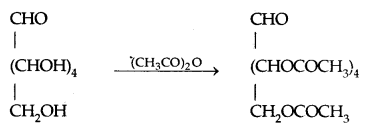
- Acetylation with acetic anhydride gives glucose pentaacetate which confirms the presence of five – OH groups attached to 5 different C atoms.
- on oxidation with nitric acid, glucose well as gluconic acid both yield a dicarboxylic acid, saccharic acid indicating the presence of -CH2OH group in it in addition to an aldehyde.
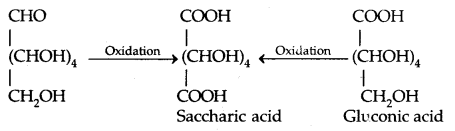
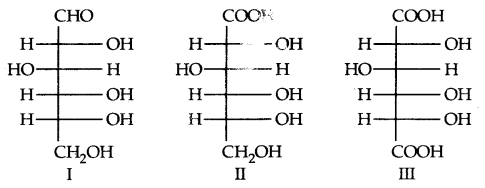
The exact spatial arrangement of different – OH groups was given by Fischer. Its exact configuration is correctly represented by I. Gluconic acid is II and Saccharic acid is III.
Glucose is correctly named as D (+) glucose. ‘D’ represents the configuration whereas (+) represents the dextro-rotatory nature of it. The meaning of D- and L- notations is given as follows:
[Note: It may be remembered that ‘D’ and ‘L’ notations have nothing to do with the optical activity of the compound.]
The letters ‘D’ or ‘L’ before the name of any compound indicate the relative configuration of a particular stereoisomer. This refers to their relationship with a particular isomer of glyceraldehyde. Glyceraldehyde contains one asymmetric carbon atom and exists in two enantiomeric forms as shown below.
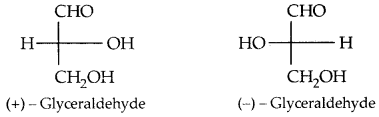
All those compounds which can be chemically correlated to (+) isomer of glyceraldehyde are said to have D-configuration whereas those which can be correlated to (-) isomer of glyceraldehyde are said to have L—configuration.
For assigning the configuration of monosaccharides, it is the lowest asymmetric carbon atom (as shown below) which is compared. As in (+) glucose, —OH on the lowest asymmetric carbon is on the right side which is comparable to (+) glyceraldehyde, so it is assigned D-configuration. For this comparison, the structure is written in a way that most oxidised carbon is at the top.
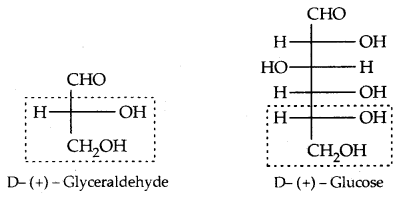
Cyclic Structure of Glucose
The structure (I) of glucose explained most of its properties but the following reactions and facts could not be explained by this structure.
- Despite having the aldehyde group, glucose does not give 2,4- DNP test, Schiff’s test and it does not form the hydrogen sulphite addition product with NaHSO3.
- The pentaacetate of glucose does not react with hydroxylamine indicating the absence of the free -CHO group.
- Glucose is found to exist in two different crystalline forms which are named a and b. The a-form of glucose (m.p. 419 K) is obtained by crystallization from a concentrated solution of glucose at 303 K while the (i-form (m.p. 423 K) is obtained by crystallisation from hot and saturated aqueous solution at 371 K,
This behaviour could not be explained by the open-chain structure (I) for glucose. It was proposed that one of the -OH groups may add to the -CHO group and form a cyclic hemiacetal structure. It was found that glucose forms a six-membered ring in which -OH at C-5 is involved in a ring formation. This explains the absence of -CHO group and also the existence of glucose in two forms as shown below. These two cyclic forms exist in equilibrium with an open-chain structure.
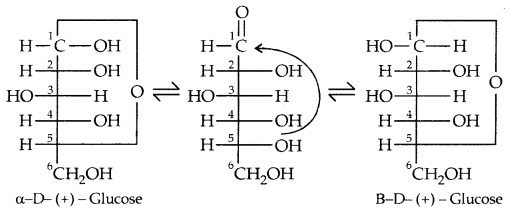
The two cyclic hemiacetal forms of glucose differ only in the configuration of the hydroxyl group at Cl, called anomeric carbon (the aldehyde carbon before cyclization). Such isomers, i.e., a-form and b-form, are called anomers.
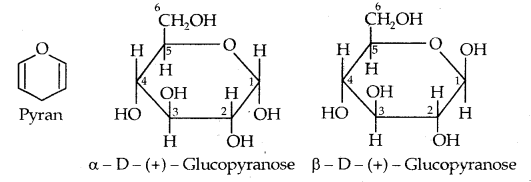
The six-membered cyclic structure of glucose is called the pyranose structure (α- or β-), in analogy with pyran. Pyran is a cyclic organic compound with one oxygen atom and five carbon atoms in the ring. The cyclic structure of glucose is more correctly represented by Haworth structure as given below:
II. Fructose
Fructose is an important ketohexose. It is obtained along with glucose by the hydrolysis of disaccharide, sucrose. It has a ketonic group at C – 2. It belongs to D-series and is a laevorotatory compound. Therefore, it is written as D – (-) fructose. Its open-chain structures are given below:
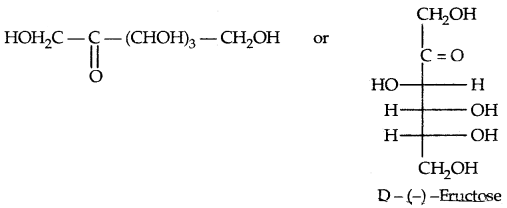
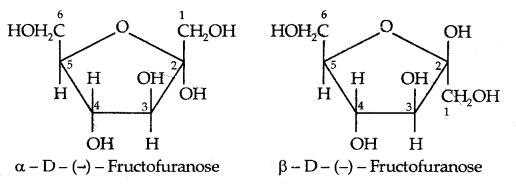
→ It differs from glucose only at C – 1 and C – 2. Its furanose form (cyclic) is:
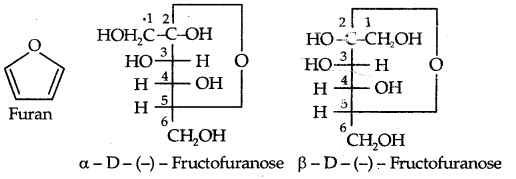
→ The cyclic structures of two anomers of fructose as represented by Haworth are given below:
Disaccharides:
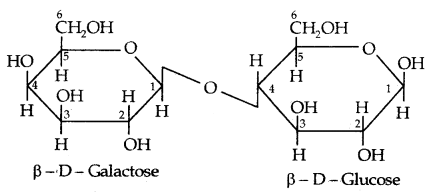
1. Sucrose: Sucrose on hydrolysis gives an equimolar mixture of D – (+) – glucose and D – (-) fructose.
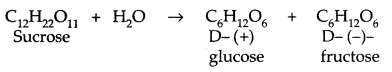
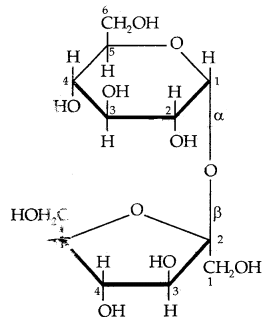
Sucrose is a non-reducing sugar. Therefore, it has a glucoside linkage between C1 of α-glucose and C2 of β-fructose.
or
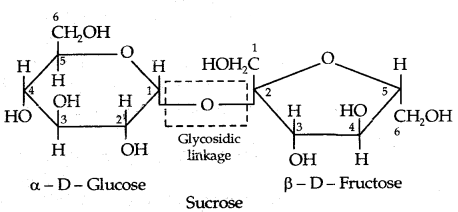
Sucrose is dextrorotatory but after hydrolysis gives dextrorotatory glucose and laevorotatory fructose. Since the laevorotation of fructose (- 92.4°) is more than the dextrorotation of glucose (+ 52.5°), the mixture is laevorotatory. Thus hydrolysis of sucrose brings about a change in the sign of rotation, from Dextro (+) to leave (-) and the product is named as invert sugar.
II. Maltose: Another disaccharide, maltose is composed of two α-D-glucose units in which C4 of one glucose (I) is linked to C4 of another glucose unit (II). Hie free aldehyde group can be produced at C1 of second glucose in solution and it shows reducing properties, so it is a reducing sugar.
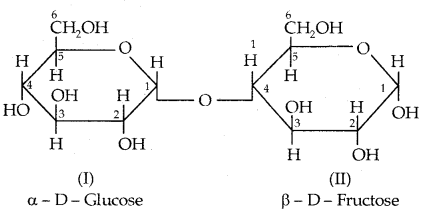
II. Lactose: It is more commonly known as milk sugar since this disaccharide is found in milk. It is composed of (β-D-galactose and β-D- glucose. The linkage is between C4 of galactose and C4 of glucose. Hence it is also a reducing sugar.
Polysaccharides: Polysaccharides contain a large number of monosaccharide units joined together by glycosidic linkages.
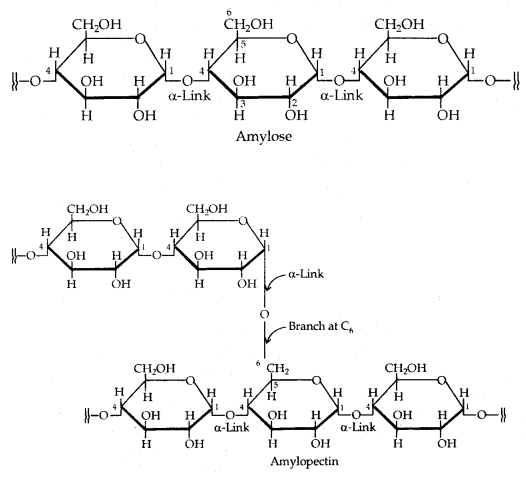
I. Starch: Starch is the main storage polysaccharide of plants. It is a polymer of a-glucose and consists of two components 15-20% of water-soluble Amylose and Amylopectin which is water-insoluble and constitutes about 80-85% of starch. Their structures have been given below:
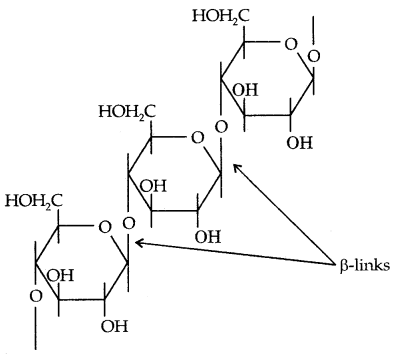
II. Cellulose: Cellulose occurs exclusively in plants. It is a predominant constituent of the cell walls of plant cells. Cellulose is a straight-chain polysaccharide composed of only β-D-glucose units which are joined by the glycosidic linkage between C1 of one glucose unit and C4 of the next glucose unit.
III. Glycogen: The carbohydrates are stored in the animal body as glycogen. It is also known as animal starch because its structure is similar to amylopectin and is more highly branched.
→ Proteins: Proteins are the most abundant biomolecules of the living system. Chief sources of proteins are milk, cheese, pulses, peanuts, fish and meat etc. They are required for the growth and maintenance of the body. All proteins are polymers of a-amino acids.
→ Amino acids: Amino acids contain an amino (- NH2) and carboxyl (- COOH) functional groups.
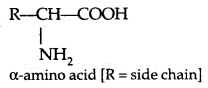
→ Classification of Amino acids: Amino acids are classified as acidic, basic or neutral depending upon the relative number of amino and carboxyl groups in their molecule. An equal number of amino and carboxyl groups makes it neutral; more amino than carboxyl groups makes it basic and more carboxyl groups as compared to amino groups makes it acidic.
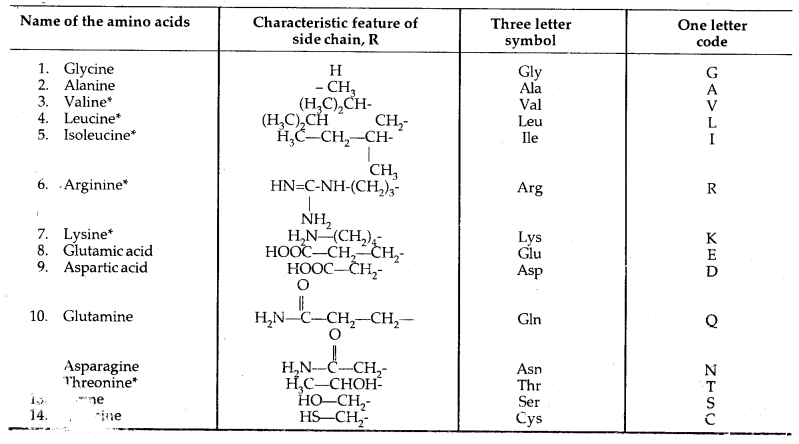
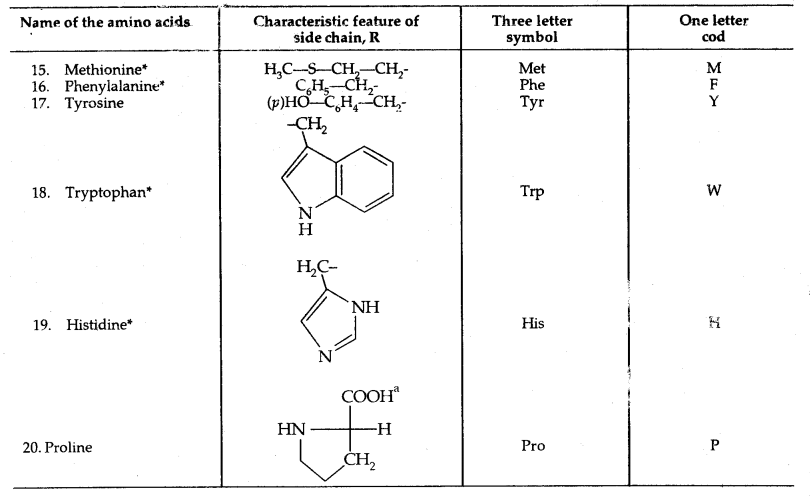
The amino acids, which can be synthesized in the body, are known as non-essential amino acids. On the other hand, which cannot be synthesized in the boxy and must be obtained through diet, are known as essential amino acids (marked with an asterisk in Table below).
Amino acids are usually colourless, crystalline solids. These are water-soluble, high melting solids and behave like salts rather than simple amines or carboxylic acids. This behaviour is due to the presence of both an acidic (carboxyl group) and a basic (amino group) group in the same molecule. In an aqueous solution, the carboxyl group can lose a proton and the amino group can accept a proton, giving rise to a dipolar ion known as a zwitterion. This is neutral but contains both positive and negative charges.
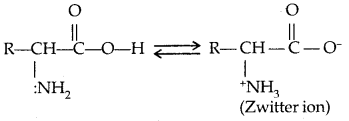
In zwitterionic form, amino acids show amphoteric behaviour as they react both with acids and bases.
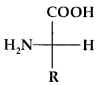
Except for glycine, all other naturally occurring a-amino acids are optically active. These exist both in D and L forms. Most naturally occurring amino acids have L-configuration. L-Amino acids are represented by writing the – NH2 group on the left hand.
Table: Natural Amino Acids,
→ Structures of Proteins: Proteins are the polymers of a-amino adds linked through peptide bond or peptide linkage.
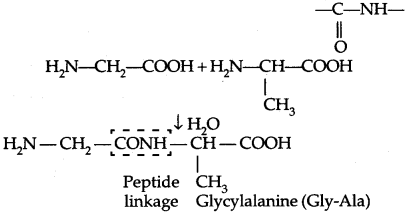
If a third amino acid combines with a dipeptide, the product is called a tripeptide. When the number of such amino acids is more than 10, then the products are called polypeptides. A polypeptide with more than 100 units of amino acid residues, having a molecular mass higher than 10,000 u is called a protein.
Proteins can be classified into two types:
(a) Fibrous proteins: When the polypeptide chains run parallel and held together by hydrogen and disulphide bonds, then a fibre-like structure is formed. Such proteins are generally insoluble in water.
(b) Globular proteins: This structure results when the chains of polypeptides coil around to give a spherical shape. These are usually soluble in water.
Insulin and albumins are common examples.
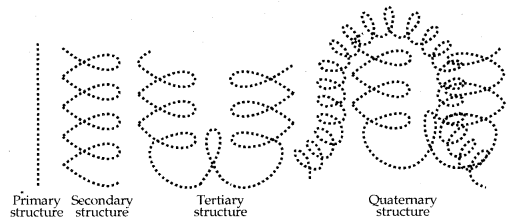
1. Primary structure of Proteins: Proteins may have one or more polypeptide chains. Each polypeptide is a protein that has amino acids linked with each other in a specific sequence and it is this sequence of amino acids that are said to be the primary structure of that protein.
2. Secondary structure of Proteins: The secondary structure of a protein refers to the shape in which a long polypeptide chain can exist. They are found to exist in two different types of structures, viz., a-helix and P-pleated sheet structure.
3. The tertiary structure of protein represents overall folding of the polypeptide chains i.e., further folding of the secondary structure. It gives rise to two major molecular shapes viz. fibrous and globular. The main forces which stabilise the 2° and 3° structures of proteins are hydrogen bonds, disulphide linkages, van der Waals and electrostatic forces of attraction.
4. Quaternary Structure of Proteins: Some of the proteins are composed of two or more polypeptide chains referred to as sub-units. The spatial arrangement of these subunits with respect to each other is known as a quaternary structure.
A diagrammatic representation of all these four structures is given in the figure below:
→ Denaturation of Proteins: When a protein in its native form is subjected to physical change like change in temperature or chemical change like change in pH, the hydrogen bonds are disturbed. The protein loses its biological activity. This is called denaturing of proteins, 2° and 3° structures are destroyed, but 1° structure remains intact. The coagulation of egg white on boiling is a common example.
→ Enzymes: The enzymes are biological catalysts produced by living cells that catalyse biochemical reactions. The enzymes differ from other types of catalysts in being highly specific and selective.
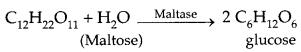
→ Mechanism of Enzyme Action: Enzymes, like catalysts, are needed only in small quantities and reduce the magnitude of activation energy of the activated complex. For example, the activation energy for acid hydrolysis of sucrose is 6.22 kJ mol-1 which is reduced to 2.15 kJ mol-1 when hydrolysed by the enzyme sucrase.
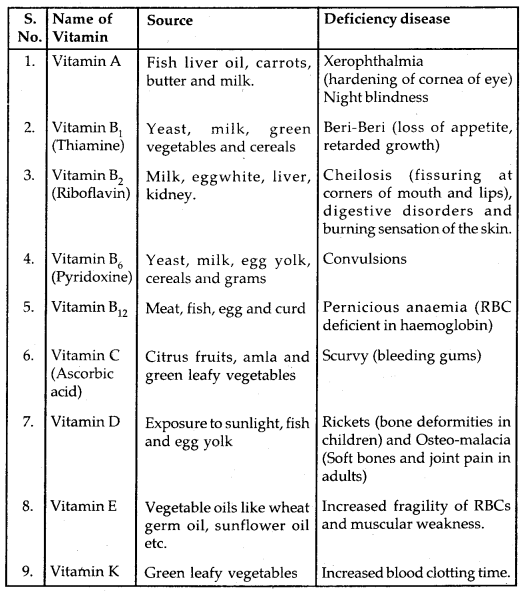
→ Vitamins: Certain organic compounds are required in small amounts in our diet but their deficiency in the body causes specific diseases. These compounds are called vitamins. In small quantities in the diet perform specific biological functions for normal maintenance of optimum growth and health of the organism.
Classification of Vitamins:
- Fat-soluble Vitamins: Vitamins like A, D, E and K are fat or oil-soluble, but insoluble in water. They are stored in the liver and adipose tissues.
- Water-soluble Vitamins: B group Vitamins and Vitamin C are soluble in water. They (except vitamin B12) cannot be stored in a body.
→ Nucleic acids: The particles in the nucleus of the cell, responsible for heredity, are called chromosomes which are made up of proteins and another type of biomolecules called nucleic acids. They are mainly of two types, deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). Since nucleic acids are long-chain polymers of nucleotides, so they are also called polynucleotides.
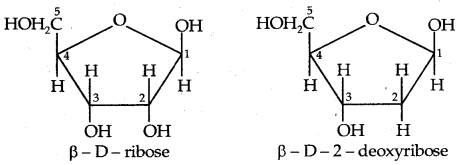
→ Chemical composition of Nucleic acids: Complete hydrolysis of DNA (or RNA) yields a pentose sugar, phosphoric acid and nitrogen
Table: Vitamins, their sources and their deficiency diseases:
containing heterocyclic compounds called bases. In DNA molecules, the sugar part is β-D-2-deoxyribose whereas, in the RNA molecule, it is β-D- ribose.
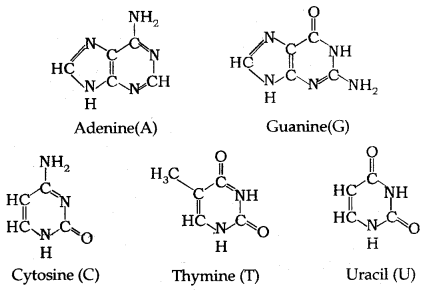
DNA contains four bases viz. adenine (A), guanine (G), cytosine (C) and thymine (T). RNA also contains four bases, the first three bases are A, G and C (as in DNA), but the fourth base is Uracil (U).
→ Structure of.Nucleic acids: A unit formed by the attachment of a base to the 1′ position of sugar is known as a nucleoside. In nucleosides, the sugar carbons are numbered as 1′, 2′, 3′ etc in order to distinguish these from the bases (Fig. (a) below). When nucleoside is linked to phosphoric acid at 5′-position of sugar moiety we get a nucleotide (Fig. (b) below)
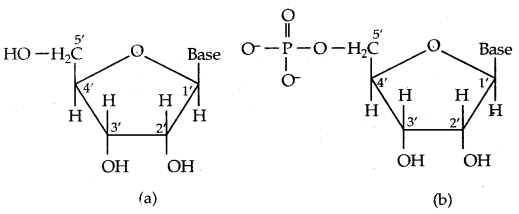
(a) Structure of a nucleoside
(b) Structure of a nucleotide.
Nucleotides are joined together by phosphodiester linkage between 5′ and 3′ carbon atoms of the pentose sugar. The formation of a typical dinucleotide is:
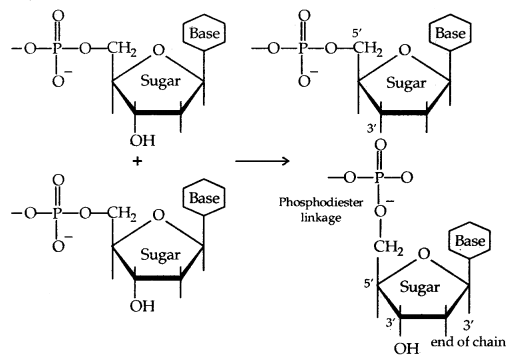
(Formation of a dinucleotide)
A simplified version of the nucleic acid chain is shown below:
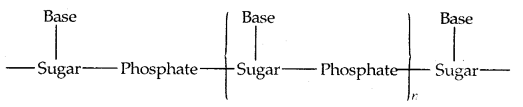
RNA molecules are of three types and they perform different functions. They are named messenger RN A (m-RNA), ribosomal RNA (rRNA) transfer RNA (f-RNA).
DNA Fingerprinting is now used:
- in forensic laboratories for the identification of criminals.
- to determine the paternity of an individual.
- to identify the dead bodies in an accident by comparing the DNAs of parents or children.
- to identify racial groups to rewrite biological evolution.
Biological Functions of Nucleic Acids: DNA is the chemical basis of heredity and may be regarded as the reserve of genetic information. DNA is exclusively responsible for maintaining the identity of different species of organisms over millions of years. A DNA molecule is capable of self-duplication during cell division, and identical DNA strands are transferred to daughter cells.
Another important function of nucleic acids is the protein synthesis in the cell. Actually, the proteins are synthesised by various RNA molecules in the cell but the message is if the synthesis of a particular protein is present in DNA.
The first one is called Replication and the second one is called protein synthesis.
- Replication: The process by which a single DNA molecule produces two identical copies of itself is called cell division or replication. Replication of DNA is an enzyme catalysed process.
- Synthesis of Proteins: Another important function of DNA is the synthesis of proteins. In fact, DNA may be regarded as the instrument manual for the synthesis of all the proteins present in a cell.
The DNA directed synthesis of proteins occurs in the following two steps:
- Transcription,
- Translation
1. Transcription: It involves copying of DNA base sequence into an RNA molecule called the messenger RNA (m RNA).
2. Translation: The mRNA directs protein synthesis in the cytoplasm of the cell with the help of r RNA and t RNA. The process is called translation.